rabbitmq集群部署
在了解了rabbitmq集群之后,来手动搭建一下rabbitmq的集群,这里以单机多节点为例,多机环境下基本上是一样的。
了解rabbitmq集群可查看 rabbitmq集群简介
集群安装环境:
- 系统:ubuntu 18.04
- 节点:3个节点,其中2个disc节点,1个ram节点
- 搭建HAProxy使集群高可用
单机环境多节点部署
此时需要机器上已安装有rabbitmq,若未安装可参考 ubuntu下安装rabbitmq及使用
由于rabbitmq集群的节点名必须唯一,所以在单机上需要用 RABBITMQ_NODENAME 设置节点名,同时也要使用 RABBITMQ_NODE_PORT 来设置监听端口以避免单台机器上端口冲突。
下面来启动三个rabbitmq节点,分别指定节点名为rabbit、rabbit1、rabbit2,端口分别为5672、5673、5674。在执行命令的时候需要禁用相关rabbitmq的插件,比如rabbitmq_management,因为虽然指定了rabbitmq的监听端口,但是其相关的插件若使用了,也会存在端口冲突,从而导致节点无法启动成功。
1 | sudo RABBITMQ_NODE_PORT=5672 RABBITMQ_NODENAME=rabbit rabbitmq-server -detached |
在启动了rabbitmq节点后,可以使用如下命令来查看各节点的状态信息(在没有指定节点前缀的时候,默认为rabbit):
1 | # rabbitmqctl [-n RABBITMQ_NODENAME] status |
使用如下命令查看集群状态信信息((在没有指定节点前缀的时候,默认为rabbit)):
1 | # rabbitmqctl [-n rabbit] cluster_status |
此处以查看节点rabbit的集群信息为例,如下所示:
1 | lazycece@cc-ubuntu:~$ sudo rabbitmqctl -n rabbit cluster_status |
如果有查看其他两个节点的集群信息,便会发现三个节点是单个独立的集群,为什么呢?因为我们还没有那个三个节点关联起来。
接下来关联三个节点到同一个集群,将rabbit1和rabbit2两个节点加入到rabbit节点所在的集群(用 stop_app 方式停止节点不会同时停止erlang环境),在将节点加入集群之前需要将节点上的数据线进行重置。因为要完成文章开始的集群目标,所以这里将rabbit设置为磁盘节点,rabbit2设置为内存节点。–ram 参数是用来指定节点是为内存节点的,在没有加该参数的情况下默认节点为磁盘节点,所以rabbit节点已然是磁盘节点。
1 | sudo rabbitmqctl -n rabbit1 stop_app |
此时查看集群状态,便能看到集群的信息了:
1 | lazycece@cc-ubuntu:~$ sudo rabbitmqctl -n rabbit cluster_status |
此时会发现,三个节点的集群已经形成了,在终端输出的信息显示了disc节点有{disc,[‘rabbit1@cc-ubuntu’,‘rabbit@cc-ubuntu’]}*,ram节点有{ram,[‘rabbit2@cc-ubuntu’]},同时还可以看见这里的集群名字为 *{cluster_name,<<”rabbit@cc-ubuntu”>>}。
搭建HAProxy
rabbitmq集群已经搭建好,已可以解决可用性和性能两方面问题,此时便需要安装HAProxy来为rabbitmq集群做负载均衡,来保障消息通信的弹性机制,以便更好的使用rabbitmq集群。
从apt包源安装HAProxy:
1 | sudo apt-get install haproxy |
此时查看haproxy的状态,可以看到其在安装后以自动启动了,信息如下:
1 | lazycece@cc-ubuntu:~$ service haproxy status |
安装完HAProxy之后,便是配置rabbitmq集群的均衡代理了。修改HAProxy的配置信息(apt源安装方式配置文件路径为/etc/haproxy/haproxy.cfg),做如下方面的配置:
- rabbitmq集群负载均衡代理
- 数据统计页面连接配置
配置修改后haproxy.cfg文件中的信息如下,global和defaults模块是原有的,这里暂时不会去修改它,listen rabbitmq_cluster 和 listen private_monitoring 两个模块是我们的配置。
1 | global |
这里来说明一下代理的服务节点的定义信息(server rabbit 127.0.0.1:5672 check inter 5000 rise 2 fall 3):
- server [name]: 后台服务器定义的内部标识;
- [ip]:[port]:连接后台服务器的ip和端口;
- check inter [value]:定义每隔多少毫秒检查后台服务器是否可用
- rise [value]:定义后台服务器出现故障后需要完成多少此健康检测才能再次被确定可用
- fall [value]:定义需要经历多少次失败的健康检测后,haproxy才会停止使用该后台服务器
到这里,rabbitm的负载均衡代理搭建与配置已经搞定了,此时访问haproxy的数据统计页面来观测haproxy的当前状态(确保已在配置中配置了数据统计的模块)。
访问地址为http://localhost:8100/stats , 我们可以看见rabbitmq集群中rabbit,rabbit1,rabbit2三个节点的状态。如下图所示:
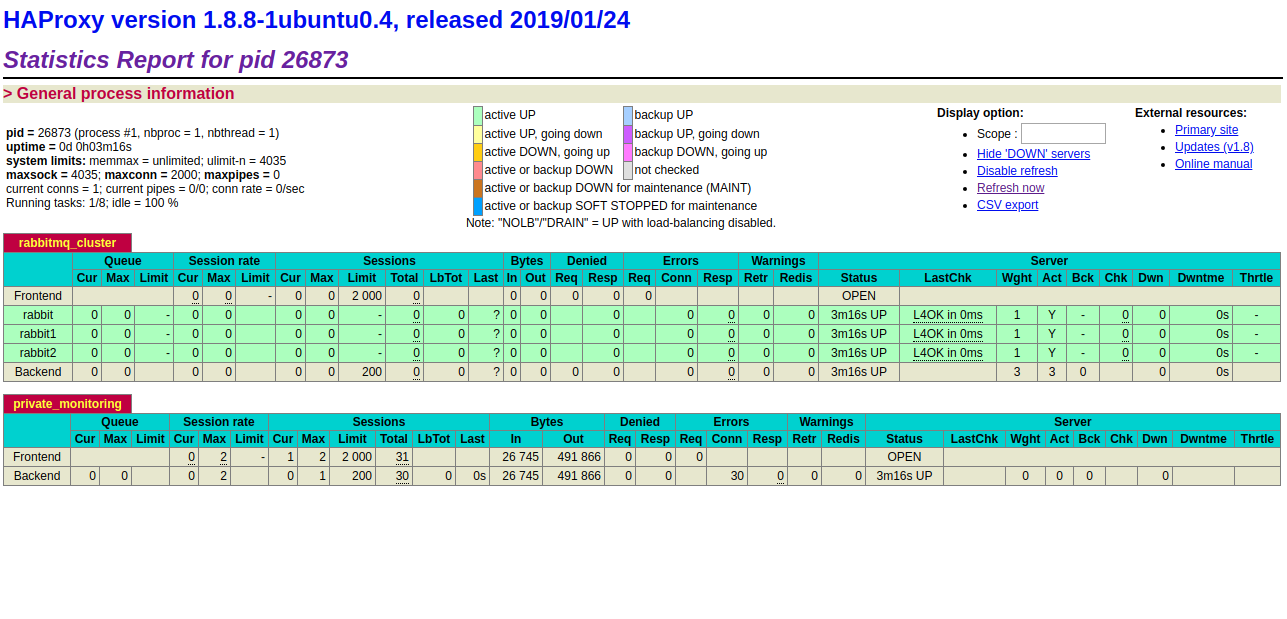
rabbitmq集群架构
rabbitmq集群到这就已部署完成,部署架构图如下所示:
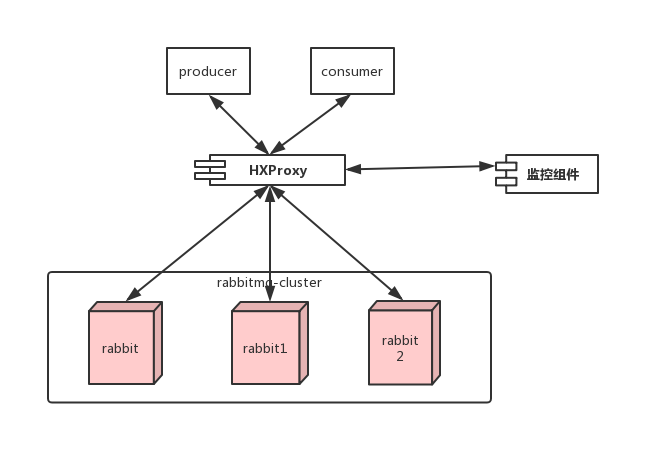
集群节点操作拓展
更改节点类型
在集群中,节点的类型是可以改变的,即ram(内存)节点与disc(磁盘)节点互相转换。假设我们想要反转rabbit1@ubuntu和rabbit2@ubuntu两个节点的类型 ,将前者从ram节点转换为disc节点,后者从disc节点转换为ram节点。为此,我们可以使用 change_cluster_node_type命令,但是要注意的是必须先停止节点。
集群操作需带上节点名称参数:sudo rabbitmqctl [-n RABBIMQ_NODENAME], 默认为rabbit
1 | # rabbit1@ubuntu 节点操作 |
创建内存节点
当一个rabbitmq节点在加入集群的时候可以被申明为内存(RAM)节点,使用rabbitmqctl join_cluster*命令,附带 *–ram 参数即可:
1 | sudo rabbitmqctl stop_app |
然后查看集群的状态:
1 | sudo rabbitmqctl cluster_status |
移除集群节点
移除集群中的节点有两种方式一种是重置节点数据,如下所示:
1 | rabbitmqctl [-n RABBITMQ_NODENAME] stop_app |
另一种是通过forget_cluster_node命令,如下所示(以节点名前缀为rabbit为例):
1 | rabbitmqctl stop_app |
集群注意事项
节点名称必须唯一
rabbitmq节点由节点名称标识,在群集中,节点使用节点名称识别并相互联系,所以群集中的节点名称必须是唯一的。
节点名称由两部分组成,前缀(通常是“rabbit”)和主机名。例如,rabbit@cc-ubuntu 是一个节点名,前缀为rabbit,主机名为cc-ubuntu。如果在给定主机上运行多个节点,那么它们必须使用不同的前缀,例如rabbit1@cc-ubuntu 和rabbit2@cc-ubuntu 。
节点启动时,会检查是否已为其分配节点名称。可以通过RABBITMQ_NODENAME环境变量设置的。如果没有显式配置任何值,则节点会解析其主机名并在其前面添加“rabbit”以计算其节点名称(rabbit@hostname)。
如果系统使用完全限定的域名(FQDN)作为主机名,则必须将rabbitmq节点和CLI工具配置为使用所谓的长节点名称。对于服务器节点,这可以通过将RABBITMQ_USE_LONGNAME 环境变量设置 为true来完成。对于CLI工具,必须设置RABBITMQ_USE_LONGNAME或必须指定--longnames选项
集群Erlang-Cookie必须一致
Erlang Cookie 是集群节点之间认证的方式。rabbitmq节点和CLI工具(例如rabbitmqctl)使用cookie来确定是否允许它们相互通信。要使两个节点能够通信,它们必须具有相同的共享密钥,称为Erlang cookie。cookie只是一串字母数字字符,最大为255个字符。所以每个群集节点必须具有相同的cookie。
cookie通常位于 /var/lib/rabbitmq/.erlang.cookie(由服务器使用)和$ HOME / .erlang.cookie(由CLI工具使用)中。请注意,由于$ HOME的值因用户而异,因此需要为将使用CLI工具的每个用户放置cookie文件的副本。这适用于非特权用户和root。
整个群集中的Erlang版本需互相兼容
集群中的所有节点必须运行相同的次要版本的Erlang:19.3.4和19.3.6可以混合,但19.0.1和19.3.6(或17.5和19.3.6)不能。各个Erlang / OTP补丁版本之间的兼容性因版本而异,但这种情况通常很少见。
集群键需开放必要的相关端口,使得网络互通
网络互通是毫无疑问的,因为rabbitmq集群内部节点直接是需要通信的。
主名名称修改时后,需要重启节点
RabbitMQ节点使用主机名相互通信,因此所有节点名称必须能够解析所有集群对等体的名称。除此之外,默认情况下RabbitMQ使用系统的当前主机名命名数据库目录。如果主机名更改,则会创建一个新的空数据库。为避免数据丢失,设置固定且可解析的主机名至关重要。每当主机名更改时,必须重新启动RabbitMQ节点。
参考文档
官方文档Clustering Guide:https://www.rabbitmq.com/clustering.html