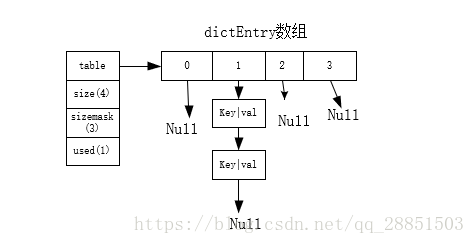
/* This is our hash table structure. Every dictionary has two of this as we * implement incremental rehashing, for the old to the new table. */ typedef struct dictht { //哈希表 dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used; } dictht;
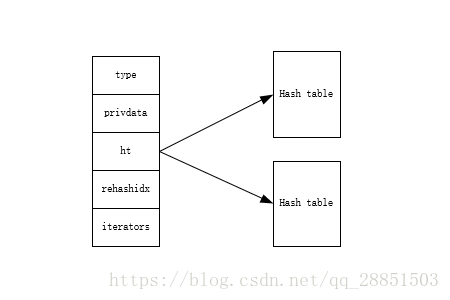
typedef struct dict { dictType *type; void *privdata; //哈希表 dictht ht[2]; //用于标记是否正在进行rehash操作 long rehashidx; /* rehashing not in progress if rehashidx == -1 */ //正在run的迭代器数量 unsigned long iterators; /* number of iterators currently running */ } dict;
/* If safe is set to 1 this is a safe iterator, that means, you can call * dictAdd, dictFind, and other functions against the dictionary even while * iterating. Otherwise it is a non safe iterator, and only dictNext() * should be called while iterating. */ typedef struct dictIterator { dict *d; long index; int table, safe; dictEntry *entry, *nextEntry; /* unsafe iterator fingerprint for misuse detection. */ long long fingerprint; } dictIterator;
其中,明确标定了需要两个hash表,这是为什么呢?从哈希表结构的定义的代码注释(Every dictionary has two of this as we implement incremental rehashing, for the old to the new table.)可知,一个用于真正存值,另一个则用于在rehash的时候使用。 字典的示意图如下:
在dict.h头文件中还有这样一行代码,其定义了字典中哈希表hash节点的初始个数为4。
1 2
/* This is the initial size of every hash table */ #define DICT_HT_INITIAL_SIZE 4
/* Add an element to the target hash table */ int dictAdd(dict *d, void *key, void *val) { dictEntry *entry = dictAddRaw(d,key,NULL);
if (!entry) return DICT_ERR; dictSetVal(d, entry, val); return DICT_OK; }
/* Low level add or find: * This function adds the entry but instead of setting a value returns the * dictEntry structure to the user, that will make sure to fill the value * field as he wishes. * * This function is also directly exposed to the user API to be called * mainly in order to store non-pointers inside the hash value, example: * * entry = dictAddRaw(dict,mykey,NULL); * if (entry != NULL) dictSetSignedIntegerVal(entry,1000); * * Return values: * * If key already exists NULL is returned, and "*existing" is populated * with the existing entry if existing is not NULL. * * If key was added, the hash entry is returned to be manipulated by the caller. */ dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing) { long index; dictEntry *entry; dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if * the element already exists. */ if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1) 计算索引值,如果元素已存在则return return NULL;
/* Allocate the memory and store the new entry. * Insert the element in top, with the assumption that in a database * system it is more likely that recently added entries are accessed * more frequently. */ ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; entry = zmalloc(sizeof(*entry)); //元素的加入总是加在索引处的第一个位置,这一步在解决hash冲突时将新加入的entry->next 指向索引上原有的第一个entry entry->next = ht->table[index]; ht->table[index] = entry; ht->used++;
/* Set the hash entry fields. */ dictSetKey(d, entry, key); return entry; } /* Returns the index of a free slot that can be populated with * a hash entry for the given 'key'. * If the key already exists, -1 is returned * and the optional output parameter may be filled. * * Note that if we are in the process of rehashing the hash table, the * index is always returned in the context of the second (new) hash table. */ static long _dictKeyIndex(dict *d, const void *key, uint64_t hash, dictEntry **existing) { unsigned long idx, table; dictEntry *he; if (existing) *existing = NULL;
/* Expand the hash table if needed */ if (_dictExpandIfNeeded(d) == DICT_ERR) return -1; for (table = 0; table <= 1; table++) { //用hash值与掩码进行与操作得出索引值 idx = hash & d->ht[table].sizemask; /* Search if this slot does not already contain the given key */ he = d->ht[table].table[idx]; while(he) { if (key==he->key || dictCompareKeys(d, key, he->key)) { if (existing) *existing = he; //已存在返回-1 return -1; } he = he->next; } if (!dictIsRehashing(d)) break; } //不存在,返回索引位置 return idx; }
/* Remove an element, returning DICT_OK on success or DICT_ERR if the * element was not found. */ int dictDelete(dict *ht, const void *key) { return dictGenericDelete(ht,key,0) ? DICT_OK : DICT_ERR; }
/* Search and remove an element. This is an helper function for * dictDelete() and dictUnlink(), please check the top comment * of those functions. */ static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) { uint64_t h, idx; dictEntry *he, *prevHe; int table;
if (d->ht[0].used == 0 && d->ht[1].used == 0) return NULL;
if (dictIsRehashing(d)) _dictRehashStep(d); h = dictHashKey(d, key);
//遍历两个hash table并删除给定值,为了避免rehash过程中,用于rehash哈希表存储了要删除的值 for (table = 0; table <= 1; table++) { idx = h & d->ht[table].sizemask; he = d->ht[table].table[idx]; prevHe = NULL; while(he) { if (key==he->key || dictCompareKeys(d, key, he->key)) { /* Unlink the element from the list */ if (prevHe) prevHe->next = he->next; else d->ht[table].table[idx] = he->next; if (!nofree) { dictFreeKey(d, he); dictFreeVal(d, he); zfree(he); } d->ht[table].used--; return he; } prevHe = he; he = he->next; } if (!dictIsRehashing(d)) break; } return NULL; /* not found */ }
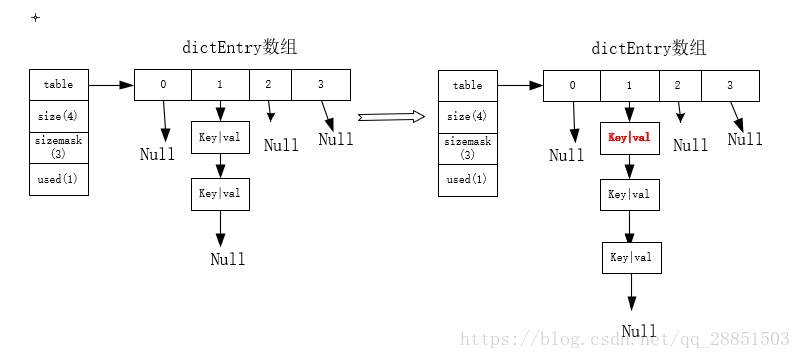
/* Performs N steps of incremental rehashing. Returns 1 if there are still * keys to move from the old to the new hash table, otherwise 0 is returned. * * Note that a rehashing step consists in moving a bucket (that may have more * than one key as we use chaining) from the old to the new hash table, however * since part of the hash table may be composed of empty spaces, it is not * guaranteed that this function will rehash even a single bucket, since it * will visit at max N*10 empty buckets in total, otherwise the amount of * work it does would be unbound and the function may block for a long time. */ int dictRehash(dict *d, int n) { int empty_visits = n*10; /* Max number of empty buckets to visit. */ if (!dictIsRehashing(d)) return 0;
/* Note that rehashidx can't overflow as we are sure there are more * elements because ht[0].used != 0 */ assert(d->ht[0].size > (unsigned long)d->rehashidx); while(d->ht[0].table[d->rehashidx] == NULL) { d->rehashidx++; if (--empty_visits == 0) return 1; } de = d->ht[0].table[d->rehashidx]; /* Move all the keys in this bucket from the old to the new hash HT */ //迁移数据 while(de) { uint64_t h;
nextde = de->next; /* Get the index in the new hash table */ //计算新索引 h = dictHashKey(d, de->key) & d->ht[1].sizemask; de->next = d->ht[1].table[h]; d->ht[1].table[h] = de; d->ht[0].used--; d->ht[1].used++; de = nextde; } d->ht[0].table[d->rehashidx] = NULL; d->rehashidx++; }
/* Check if we already rehashed the whole table... */ if (d->ht[0].used == 0) { //如果整个rehash操作已完成,则将h[1]和h[0]互换位置 zfree(d->ht[0].table); d->ht[0] = d->ht[1]; _dictReset(&d->ht[1]); d->rehashidx = -1; return 0; }