以下涉及到的源码均为redis5.0-rc3版本的代码【点击查看官方源码】
redis对象
在redis中,定义了5中基本对象,分别为string、list、set、zset、hash。而为了方便管理与操作,redis又对这5种对象进行了一次外围封装,如下所示(server.h头文件):
1 | typedef struct redisObject { |
由此可见,是通过redisObject这个结构来统一对象的入口,由type字段来标识当前对象的本质(string、list、set、zset、hash),并由encoding字段来标识对象的底层具体实现数据结构,refcount字段则是用于引用计数,使得对象可以共享。
redis对象类型的宏定义如下所示:
1 | /* Redis 对象 */ |
redis编码类型的宏定义如下所示:
1 | /* 对象编码 */ |
redis对象与基本对象及其底层编码实现之间的关系可以简单得用一个图来简略的表述,如下所示: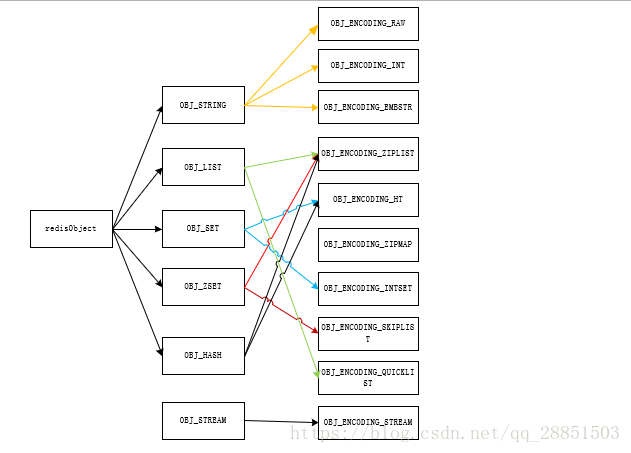
特点
- 引用技术和对象共享。从redisObject的结构中可以看出,有一个refcount字段,这个字段主要是用于对象的计数,从而达到对象的共享,以及对象释放。
- 命令的类型检查。由于有些命令只能在部分结构上使用,而通过redisObject对象来操作的时候便需要进行区分,这时候type字段就有用了,它标识了具体的对象,便能表明命令是否可执行。
- 命令多态。因redis的基本对象都不止由一种类型编码实现,所以在执行一个操作的时候,都存在多态的情况,这时encoding字段的重要性就凸显了。
源码解读
这里粗略的解读一下redis对象操作的源码,以此来说明以下几个点:
- 对象的创建
- 类型检查
- 多态
- 引用技术与对象共享
- 内存释放
(注:如下相关的代码如非特定说明则均存在object.c文件中)
对象创建
通过查看此部分代码,可以知道每种基本对象的底层数据结构编码情况。
创建对象的基本代码如下所示:
1 | robj *createObject(int type, void *ptr) { |
创建String类型的对象
在创建字符串的时候用OBJ_ENCODING_EMBSTR_SIZE_LIMIT来标明区分具体的底层实现是sds或者emdstr类型。
1 | /* raw类型编码 */ |
创建List类型的对象
1 | /* quicklist类型编码 */ |
创建Set类型的对象
1 | /* ht类型编码 */ |
创建ZSet类型的对象
1 | /* skiplist类型编码 */ |
创建Hash类型的对象
1 | /* ziplist类型编码 */ |
创建Module类型的对象
1 | robj *createModuleObject(moduleType *mt, void *value) { |
创建Stream类型的对象
1 | robj *createStreamObject(void) { |
内存释放
对象的释放体现了引用计数的重要性,也体现了对象共享的问题。如下时各对象的释放操作。这里我们重点关注decrRefCount操作函数,其通过判断一个对象是否仍然被共享,如果没有就进行内存释放。
1 | void decrRefCount(robj *o) { |
引用计数限定
redis对对象共享的引用计数进行了限定,在server.h头文件中宏定义了最大引用计数:
1 | #define OBJ_SHARED_REFCOUNT INT_MAX |
当一个对象的被引用数量没有到达最大值时,才可以被继续引用。如下所示:
1 | void incrRefCount(robj *o) { |
对象共享
引用计数体现了对象共享,除了创建的对象的引用计数外,redis还默认初始化了一些共享的常量,仔细读过前面内容的会发现,在创建字符串对象中我贴出了如下的这个函数:
1 | robj *createStringObjectFromLongLong(long long value) { |
这个函数中就体现了redis默认初始化的共享量,当整数值小于OBJ_SHARED_INTEGERS常量时,则直接进行共享引用计数加1,而该常量在server.h头文件宏定义如下:
1 | #define OBJ_SHARED_INTEGERS 10000 |
如下时redis默认初始化的共享量(server.h头文件中),其具体的初始化在createSharedObjects函数中实现(server.c文件中)。
1 | struct sharedObjectsStruct { |